Was hinter Deep Learning steckt

Wie kann ChatGPT Texte erzeugen? Wie können KI-Programme Bilder generieren? Die dahinter liegende Technologie nennt sich Deep Learning.
Ein Gastbeitrag von Jan Ebert, Software Engineer and Researcher Large-Scale HPC Machine and Deep Learning, Forschungszentrum Jülich
Für die aktuelle KI-Revolution sind vor allem Deep Learning und große Sprachmodelle (LLM) verantwortlich. Es ist wichtig, die technischen Grundlagen zu verstehen, denn nur mit dem nötigen Wissen können wir die aktuelle Situation und künftige Entwicklungen begreifen. Wie funktioniert Deep Learning also überhaupt?
Kurz gesagt: Es ist Mathematik.
Dieser Artikel stellt die wichtigsten technischen Grundlagen von Deep Learning, neuronalen Netzen und mehr vor.
Was versteht man unter Deep Learning?
Die Kombination aus
- einer großen Anzahl einstellbarer Parameter,
- einer Funktion mit bestimmten mathematischen Eigenschaften
- einer großen Menge an Daten, von denen gelernt werden soll (mindestens 10.000 Beispiele)
- eine Art von Vergleichsfunktion/Fehlermaß, und
- ein gradientenbasierter Optimierungsalgorithmus (Erklärung folgt in Kürze),
ergibt einen sehr flexiblen Algorithmus, der alle möglichen Probleme lösen kann (einschließlich der Vorhersage der menschlichen Sprache!). Die Technologie, die hinter Deep Learning steht, wird als neuronales Netz bezeichnet.
Hinter der "Magie" der neuronalen Netze verbergen sich lediglich Zahlen, die wir addieren, multiplizieren und auf die wir einige elementare mathematische Funktionen anwenden. Ihre erstaunliche Leistungsfähigkeit ergibt sich aus der Art und Weise, wie diese Mathematik zwischen vielen Zahlen selbst sehr abstrakte Konzepte erfassen kann.
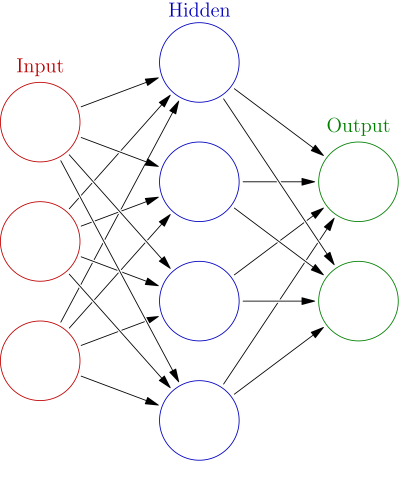
Das Diagramm hier zeigt ein neuronales Netz mit mehreren Schichten.
- Die Eingabeschicht verarbeitet die Daten in einem neuronalen Netz.
- Die Ausgabeschicht verarbeitet alle Eingabewerte in ein bestimmtes Ausgabeformat.
- Jede andere Schicht wird als verborgene Schicht bezeichnet. In diesem Fall handelt es sich um ein neuronales Netz mit einer einzigen verborgenen Schicht.
Jeder Kreis ist ein Neuron, und die Pfeile zwischen ihnen stellen die Verbindung zwischen diesen Neuronen dar: ähnlich der menschlichen Synapsen. Wie zu sehen ist, stellen verschiedene Eingangsneuronen Verbindungen zu den Neuronen der verborgenen Schicht her, die wiederum Verbindungen zu den Ausgangsneuronen aufbauen. Zwischen diesen Verbindungen werden die Informationen weitergeleitet.
Im Fachjargon für neuronale Netze stößt man häufig auf den Begriff "Gewicht", was die Intensität der Verbindung darstellt.

Fast alle modernen neuronalen Netze sind "differenzierbar", das heißt, Ableitungen sind möglich. Eine Ableitung ist die Richtung, in die sich die Kurve bewegt, wenn der Input (das x in f(x)) leicht verändert wird. Dies ist die wichtigste mathematische Eigenschaft, die unser Modell haben muss.
Eine weitere Voraussetzung ist die Vergleichsfunktion, die wir bereits erwähnt haben. Um etwas zu verbessern, müssen wir wissen, ob wir tatsächlich besser oder schlechter geworden sind. Bei sehr einfachen Fragen können wir zum Beispiel prüfen, ob wir korrekt mit Ja oder Nein geantwortet haben. In der Mathematik können wir außerdem messen, wie weit wir vom richtigen Ergebnis entfernt sind. Wir wollen den Fehler, den wir mit dieser Vergleichsfunktion messen, minimieren. Und dazu benötigen wir Differenzierbarkeit.
Der stochastische Gradientenabstieg ist ein Optimierungsalgorithmus, der wie folgt funktioniert:
- Zuerst wird die Ableitung der Funktion, die optimiert werden soll, berechnet. Das ist sehr ähnlich zu dem, was Sie vielleicht in der Schule gemacht haben; beim Deep Learning machen wir das nur für viele x auf einmal. Um LLMs zu trainieren, machen wir das für außerordentlich viele x auf einmal.
- Folgen Sie der Ableitung in umgekehrter Richtung und machen Sie einen "Optimierungsschritt". Wir verschieben x so, dass f(x) hoffentlich "besser" wird, also unserem eigentlichen Ziel näher kommt. Für ein LLM würde dies bedeuten, dass wir alle seine Parameter ein wenig verschieben, in der Hoffnung, dass die daraus folgenden Texte besser werden.
- Wiederholen SIe die Schritte, bis Sie mit dem Ergebnis zufrieden sind.
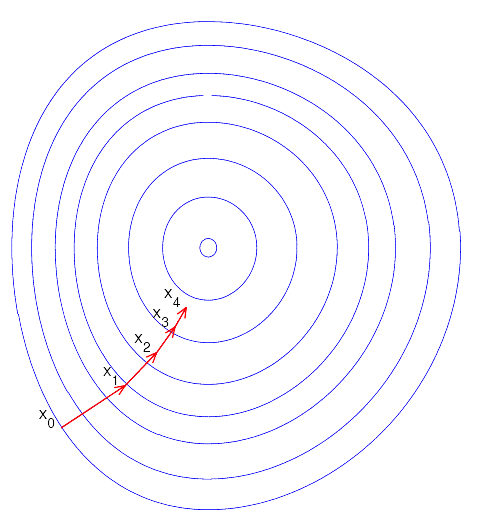
Dieses Diagramm veranschaulicht die Schritte einer sehr gut funktionierenden Gradientenabstiegsoptimierung. Woher kommt der Name? Die Ableitung für viele Eingaben wird auch als Gradient bezeichnet, und die Optimierungsschritte verlaufen in Richtung des Minimums des gemessenen Fehlers.
Die Geschichte des Deep Learnings
Erstaunlicherweise wurde die grundlegende Methodik, die wir heute verwenden, schon sehr früh entwickelt.
So wurde beispielsweise das Neocognitron, ein Bildverarbeitungsmodell, zur Erkennung handgeschriebener japanischer Schriftzeichen eingesetzt. Im Jahr 1997 wurde das LSTM-Modell (Long Short-Term Memory) veröffentlicht, ein sequentielles Modell, das Probleme lösen kann, die Kenntnisse über die Vergangenheit erfordern. Es ist wichtig zu betonen, dass diese Modelle selbstlernend waren; die Leistung wurde den Modellen nicht manuell einprogrammiert. Stattdessen lernten die Modelle anhand von Beispielen und konnten daraus Schlüsse ziehen.
TDas LSTM ist für uns von besonderem Interesse, weil es 20 Jahre lang das Sprachmodell der ersten Wahl war und die beeindruckendsten Ergebnisse lieferte. Obwohl es auch für andere Aufgaben im Bereich der natürlichen Sprachverarbeitung eingesetzt wurde, wurden seine größten praktischen Erfolge in der natürlichen Sprachverarbeitung erzielt. Schon bald verwendete jedes Telefon LSTMs, um das nächste Wort, das man tippen wollte, vorherzusagen oder um die geschriebene Sprache zu erkennen.
In der dritten Welle, die in den späten 2000er Jahren begann, revolutionierten die Fortschritte bei der Computerhardware und die Menge der leicht verfügbaren Daten schließlich das Deep Learning und machten es zu dem wichtigen und weit verbreiteten Bereich, der es heute ist. LSTMs und Vision-Modelle begannen, Wettbewerbe in Forschungsherausforderungen zu gewinnen, schlugen alle früheren Methoden, die auf jahrzehntelanger manueller Entwicklung basierten, und machten den Menschen die Macht des Deep Learning und der künstlichen Intelligenz bewusst.
Heute, im Jahr 2024, können wir feststellen, wie weit der Bereich des Deep Learning in den letzten 100 Jahren vorangeschritten ist und sich zum Rückgrat eines der wichtigsten Paradigmenwechsel entwickelt hat, die wir derzeit erleben.
Weitere Informationen
Wenn Sie das Thema gepackt hat und Sie mehr über Deep Learning und ihre Anwendungen wissen möchten: Jan Ebert hat im Rahmen unserer Vortragsreihe "HIDA Lecture Series on AI and LLMs" eine Präsentation gehalten, die wir aufgezeichnen haben.
Aufzeichnung anschauen (YouTube-Video)
Zudem haben Sie auch die Möglichkeit, die vorgestellten Folien mit allen Informationen hier herunterzuladen:
Folien herunterladen (Zip-Datei)